
【关键字】
军队军工
本文发表于《指挥信息系统与技术》2023年第2期
作者:马雷鸣,张道伟
引用格式:马雷鸣,张道伟. 联合作战模式下的信息过滤方法[J]. 指挥信息系统与技术,2023,14(2):76-80.
摘要
信息化作战是当前主要作战方式之一,面向弱连接、高实时和资源受限的战场边缘网络环境,以信息化技术为主导建立陆军、海军和空军各兵种间可靠的和互连互通的协同作战模式成为联合作战研究热点。基于信息文本的虚词特征,提出了一种联合作战模式下的信息过滤方法,通过模拟各军兵种在云-边-端协同模式下的信息过滤,既降低了作战资源占用率又保障了作战信息文本的高实时与唯一性。
0 引言
联合作战指在现代战场信息互连互通环境下的陆军、海军和空军等军兵种之间协同作战的模式。针对战术边缘弱连接、高动态和高实时的网络环境下各军兵种联合作战需求,可通过建立云-边-端协同架构实现边缘战术信息的可靠传输。军事领域中,云的网络环境稳定,计算存储能力充足,并可按需共享存储和通信网络等资源;边的资源较少,且部署在战术边缘;端由嵌入式终端、平板和手机组成,轻量便携。
信息过滤一直是热门研究问题,在资源受限的联合作战模式下,如何有效对重复的作战信息进行过滤不仅能够节省资源,更是高实时和高动态的作战实情的基本要求。目前,信息过滤方法可分为以下3种类型:
1) 基于URL(统一资源定位符)的过滤方法。该类方法基于以下假设:具有相同URL的网络资源一般是相同的。多军兵种联合作战模式下重复的作战信息的URL相同的概率更低,因此该类方法应用较广,其中常用的URL过滤方法是基于布隆过滤器进行去重。
2) 基于协同的过滤方法。该类方法以用户为基础,基于用户的行为数据挖掘用户喜好,从而筛选内容,其中最近邻协同过滤技术是目前常用技术之一。
3) 基于内容的过滤方法。该类方法利用文本内容进行相似识别,从信息文本中提取一组特征,并基于特征进行降维后再进行相似度比较,从而判断是否需要过滤。
1 相关工作
英文文本过滤去重起源于20世纪70年代学术界存在的代码重复问题,目前国外英文文本相似性检测系统较多,其中常用的是iParadigms 公司开发的基于数字指纹的Tumitin平台。汉语文本相似检测最早由何云峰团队研发,之后潘谦红等提出了一种基于属性论的文本相似度计算方法。Simhash算法是Google公司进行海量去重的主要算法,其实质是降维技术,但在战术边缘环境下,计算资源有限且工作量繁重。基于协同过滤的算法通过推测用户喜好进行选择性信息过滤,由于战场信息瞬息万变且无法准确推测用户喜好,故不适用于联合作战模式下的信息过滤。
云-边-端架构中,云由各级中心云构成,其网络环境稳定,并可按需共享通信网络等资源;边指覆盖了各级各类业务信息系统的边缘云,并可利用有限资源构建高内聚的服务能力;端由平板和手机等终端组成,具有轻量便携的特征。边对上可与中心云互连,对下可为终端用户提供伴随式服务,也可与其他边互连,共同形成云-边-端的协同架构。鉴于此,本文提出了一种联合作战模式下的信息过滤方法,先基于虚词提取作战信息样本,再通过样本组成特征码,最后利用余弦相似度比较文本相似度。试验结果表明,该方法适用于计算和存储资源有限的联合战场环境。
2 基于虚词的信息过滤方法
联合作战模式下的信息过滤方法(本文方法)可对作战信息进行过滤,重复阈值以文献提出的阈值为标准:如果2篇文章之间有超过80%的用词相同,则这2篇文章是重复的。本文方法流程如图1所示,包括以下3个阶段:1) 构建云-边-端架构下的协同作战模式,自主形成云-边协同、边-边协同、云-端协同和端-端协同模式,并将各模式下的作战信息汇聚至样本库;2) 对样本库中的作战信息进行特征提取,并对作战信息样本进行抽取;3)对作战信息样本进行特征码提取,并基于余弦相似度进行过滤操作,最终形成不含重复信息的作战信息库。
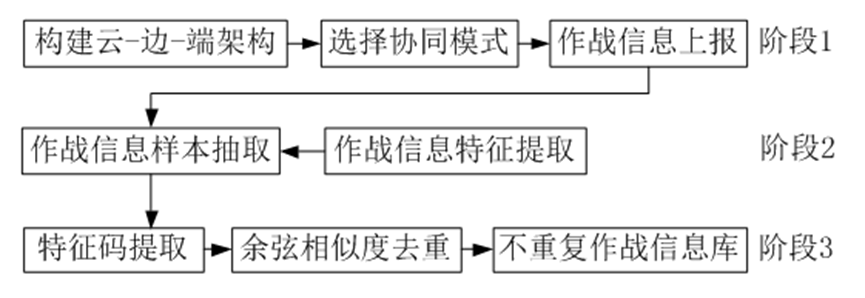
图1 本文方法流程
2.1 云-边-端架构
在资源受限、窄带宽和弱连接的战场网络环境中,构建云-边-端架构是实现战场可靠通信的有效途径。当网络通信情况良好时,云可向下连接边以形成云-边协同,边可向下连接端以形成边-端协同,同时通过上下级同步实现作战信息同步;当边和端因窄带宽等原因造成与上级中心连接断开时,可自动切换为采用对等协同模式随遇接入可连接的自组网络并共享资源,从而实现云-边-端架构下多种模式的无缝切换。云-边-端架构如图2所示。

图2 云-边-端架构
2.2 作战信息特征提取
多数作战信息文本会分段描述,而每个段落均占一定篇幅并出现大量虚词,因此可基于虚词提取作战信息样本,并基于样本比较2条作战信息是否重复。基于上述推测,本文利用文献给出的在线网络中的常用虚词表对作战信息特征进行了提取。常用虚词表如图3所示。
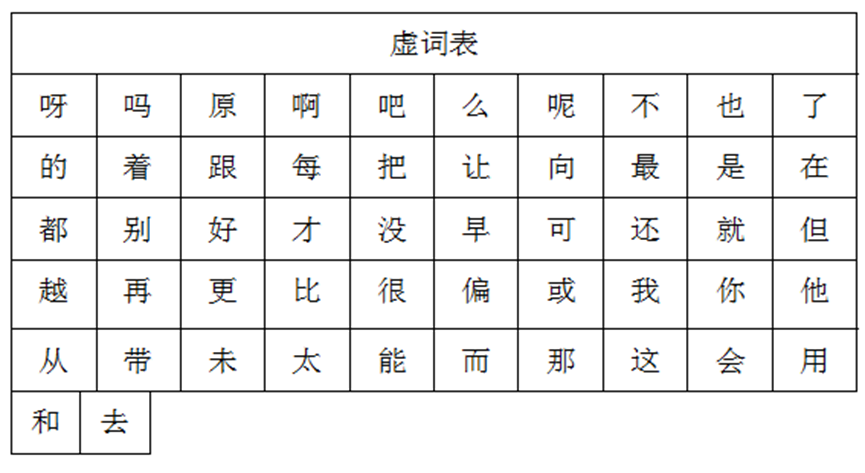
图3 常用虚词表
2.3 作战信息样本抽取
大部分信息样本均具有虚词数不少于3个的段落。基于此,本文初步假设以比较作战信息样本是否重复作为作战信息过滤的判定依据是合理的。本文从军事新闻网站抓取2则信息,标记为作战信息1和作战信息2,如图4和图5所示。为了便于描述,定义如下:含虚词数不少于3的自然段称大段落(big paragraph);字数不少于L的自然段称长段落(long paragraph),若取L=20,则字数不少于20的自然段就是长段落。

图4 作战信息1

图5 作战信息2
基于上述定义,本文对样本库中的作战信息顺序进行了读取并统计了大段落,将前3个大段落存入数据库作为样本以便后续试验,如作战信息1;对于篇幅较短且含大段落少于3个的情况进行特殊处理,如作战信息2,重新遍历将前几个长段落补齐3个组成为样本。提取的作战信息1样本和作战信息2样本如图6和图7所示。

图6 作战信息1样本

图7 作战信息2样本
2.4 特征码提取

2.5 相似度比较

2.6 评价标准

3 试验与分析
为了验证本文方法的实际效果,本文从中国军网随机抓取新闻正文以生成文本样本。为了确保试验的准确性,抓取了同类别文本样本和不同类别文本样本2组数据。其中,样本1为同类别文本样本,指类别选择为军事的样本,共计10 000条;样本2为不同类别文本样本,指选择类别为陆军、海军、空军、火箭军和联勤的样本各2 000条,共计10 000条。本文方法信息过滤流程如图8所示。

图8 本文方法信息过滤流程
3.1 试验步骤与结果
对样本库中的模拟作战信息文本进行以下操作:
1) 模拟云-边-端协同模式,在试验环境下通过笔记本、平板和手机分别模拟云、边和端,并构成三层架构的协同关系,2台手机模拟端-端对等协同关系,每次点击“同步”时向同一数据库发送作战信息样本;
2) 依次读取样本库内作战信息样本,统计含虚词数是否不少于3,若是则记为大段落并保留,若大段落数不少于3,则将前3段作为样本,停止读取;若读到最末行,大段落数仍少于3则从头读取,取最长的数个段落补齐3段作为样本;
3) 提取样本特征码,并对2)中的样本进行分割,并将其中虚词和标点符号替换为空格;
4) 基于3)的特征码比较余弦相似度,设定余弦相似度值为阈值,超过阈值则判定为重复文本;
5) 对样本1和样本2分别进行试验,试验结果如图9所示。由图9(c)可知,样本1当阈值为0.82时, 值达到最大值,此时的准确率P、召回率R和F1值分别为98.7%、100%和99.3%;样本2当阈值为0.78时, 值达到最大值,此时的准确率 、召回率 和 值分别为98.4%、100%和99.2%。

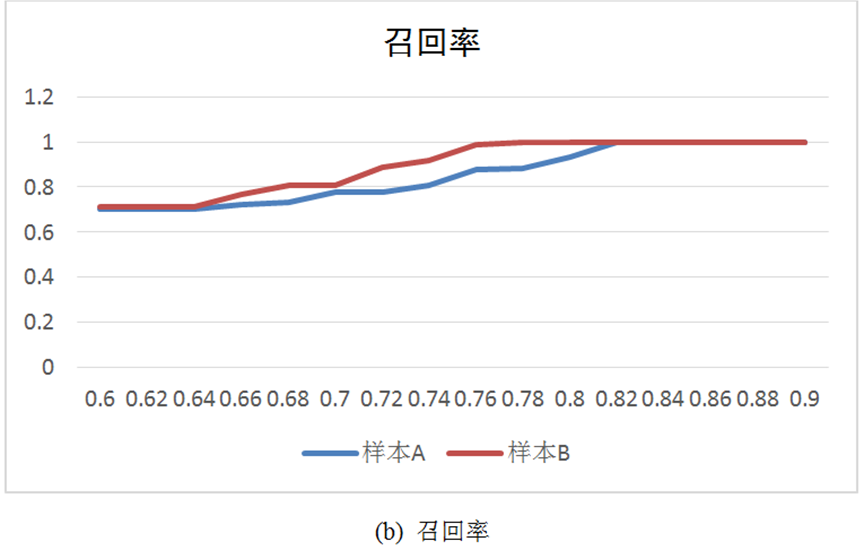
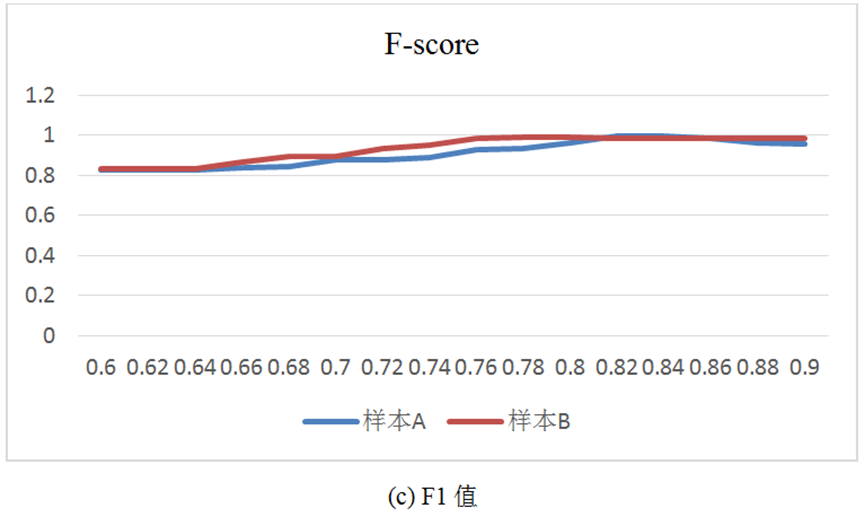
图9 不同余弦相似度阈值下的评价指标
3.2 试验分析
本文方法通过虚词将大文本样本简化为特征段,并使用余弦相似度进行相似度比较,既简化了计算又节省了计算资源。试验结果可见,本文方法在同类样本和不同类样本上的准确率P、召回率R和F1值均达到了98%以上,确保了作战资源获取的唯一性;通过对重复信息进行过滤,降低了资源占有率,适应了资源受限的联合战场环境。
4 结束语
本文基于虚词和余弦相似度对联合作战模式下的信息过滤方法进行了研究,并通过模拟自主切换的云-边-端协同模式,对不同类型样本进行了作战信息过滤试验。本文方法通过对作战信息进行降维提高了文本相似度对比效率。试验结果验证了基于虚词和余弦相似度的方法可对作战信息进行有效过滤,可节约边缘战术环境下的计算与存储资源。
上一篇 : 境外认知战作战力量及技术装备综述
下一篇 : 没有了
Copyright © 2016 云安全门户 | 南京聚铭网络科技有限公司 旗下产品 | 苏ICP备16021665号-2
Copyright © 2016 云安全门户
南京聚铭网络科技有限公司 旗下产品